Why PLS-SEM and SEMinR?
HCI research is about latent variables - so is PLS-SEM
HCI research is heavily informed by behavioural research and applied psychology. It often focuses on the traits, beliefs, and perceptions of the examined individuals. These are so-called latent variables which means that they cannot be directly observed or measured. Rather, they must be inferred or measured indirectly using measurable or observable variables.
Variables that cannot be measured directly are especially common in HCI research conducted on humans. For example, self-efficacy is a concept used a lot throughout psychology and HCI. It refers to an individual’s belief in their own capabilities to perform a certain action and reach certain goals (Bandura et al. 2006). This belief is a latent variable or latent construct. It cannot be measured directly but must be inferred from (or operationalized through) survey items that measure the manifest symptoms of self-efficacy (Bandura et al. 2006).
PLS-SEM can be used for this inference
Empirical research in HCI requires rigorous, and versatile methods that can incorporate not only observable variables, but also latent variables, and design variables. PLS-SEM is uniquely placed to meet this requirement in that it can simultaneously estimate how these latent variables are constructed from their indicators, and how the variables relate to each other, therefore producing consistent and unbiased results (Hair, Ringle, and Sarstedt 2011). The dual explanatory and predictive nature of PLS-SEM makes it relevant not only to scientific researchers but also to practitioners interested in predictive modelling.
What is the result of a PLS-SEM analysis? You have probably seen research papers using path models such as the followng. These are the outputs of structural equation modeling and can be generated using SEMinR.
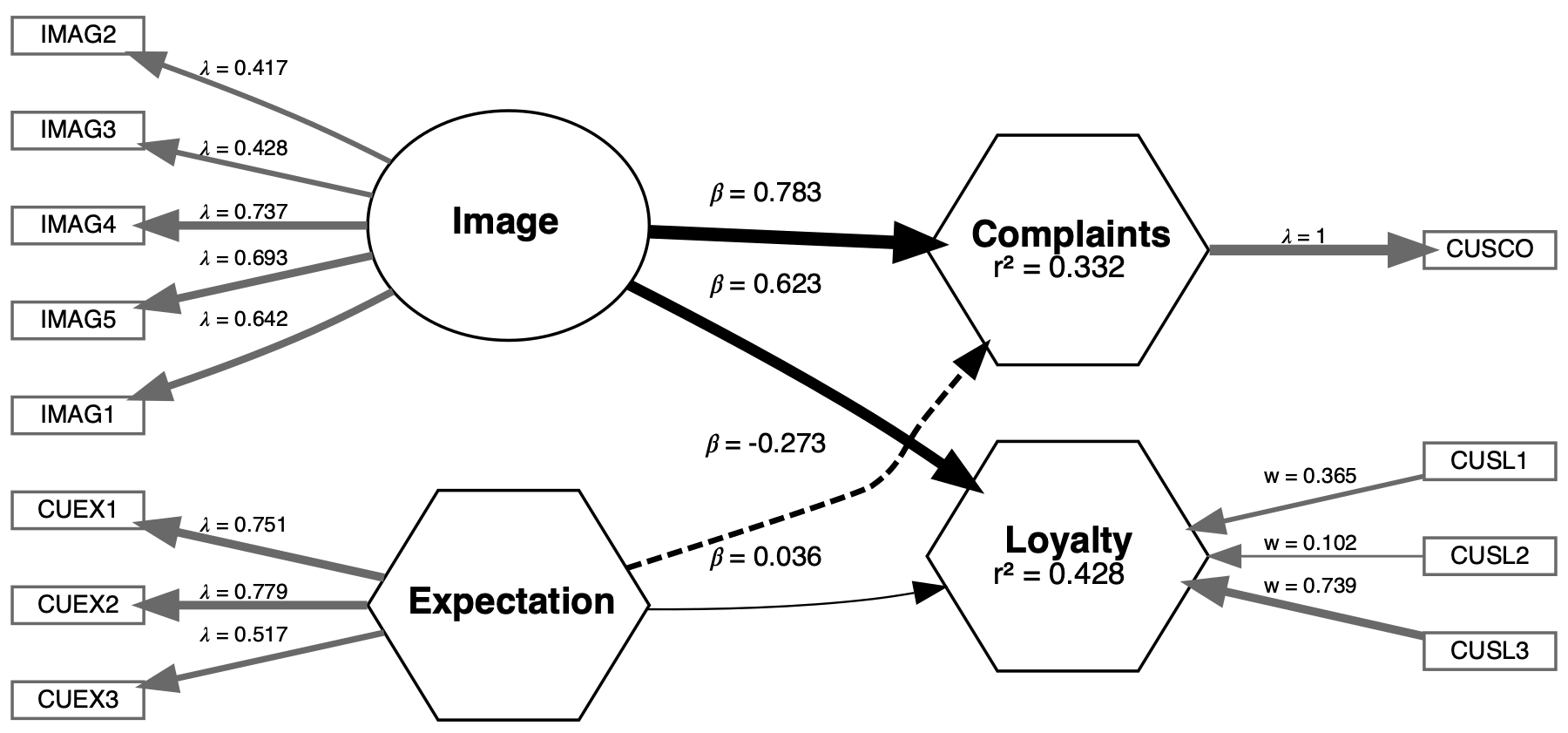
The role of SEMinR in this process
SEMinR is an R package designed to make structural equation models (SEM) approachable to practitioners across disciplines. It is an open-source and free tool that practitioners can use immediately with minimal setup. SEMinR’s syntax offers a domain-specific language to define structural equation models using R syntax. The syntax is designed with the needs and knowledge of SEM practitioners foremost in mind. While we focus on partial least squares structural equation modelling (PLS-SEM) in this tutorial, SEMinR also includes covariance-based SEMs and covariance-based confirmatory factor analysis. SEMinR has functions named after the major features of a SEM model. For example, consider a PLS-SEM model that has several composite or reflective constructs that are measured by multiple items (e.g., survey questions), with causal paths from a certain set of constructs to others. The syntax for this model might look like this:
measurements <- constructs(
reflective("Image", multi_items("IMAG", 1:5)),
composite("Expectation", multi_items("CUEX", 1:3)),
composite("Loyalty", multi_items("CUSL", 1:3), weights = mode_B),
composite("Complaints", single_item("CUSCO")))
structure <- relationships(
paths(from = c("Image", "Expectation"), to = c("Complaints", "Loyalty"))Comparing our description of the model to the syntax, we can see that the functions we use correspond to the nomenclature of SEM models that practitioners use: the measurement model is defined using functions called constructs(), reflective(), composite(), and multi_items(); and the structural model is defined by functions using relationships(), and paths(). This makes SEMinR’s syntax highly readable and interpretable to new and expert SEM practitioners alike.